

Witamy w serii „Wgląd w Safina AI”! Tutaj otrzymasz ekskluzywne spojrzenie za kulisy technologii napędzającej naszego asystenta telefonicznego AI. Seria jest skierowana do specjalistów technicznych, architektów systemów i wszystkich, którzy chcą wiedzieć, jak powstają solidne, przeznaczone dla firm rozwiązania AI do obsługi głosu. W dzisiejszym świecie biznesu telefonia to już nie tylko łączenie połączeń. Chodzi o tworzenie inteligentnych, responsywnych i zautomatyzowanych doświadczeń. AI, która odbiera połączenia, rezerwuje terminy i odpowiada na złożone pytania, potrzebuje architektury nastawionej na szybkość, niezawodność i głęboką integrację. W tej serii przyjrzymy się kluczowym komponentom „mózgu” i „układu nerwowego” Safiny.
Seria „Wgląd w Safina AI”
- Część 1: Architektura bazowa – AI głosowa w czasie rzeczywistym (jesteś tutaj)
- Część 2: Mózg – Kontekst vs. RAG dla wiedzy firmowej
- Część 3: Zmysły – Multimodalne wejścia z technologią mowy-na-tekst (STT)
- Część 4: Głos – Naturalny tekst-na-mowę (TTS) z niskim opóźnieniem
Wyzwanie: Rozmowy w czasie rzeczywistym to więcej niż zapytanie-odpowiedź
Zapytanie webowe realizuje prosty schemat: zapytanie, przetwarzanie, odpowiedź. Rozmowa w czasie rzeczywistym jest fundamentalnie inna. To ciągły, dwukierunkowy strumień danych, w którym opóźnienie nie jest jedynie metryką wydajności, lecz centralną częścią doświadczenia użytkownika. Już opóźnienie o kilkaset milisekund może sprawić, że AI wydaje się powolna i nienaturalna. Dlatego metryki takie jak Time to First Token (TTFT) i Time to First Byte (TTFB) są kluczowe:
- TTFT (Time to First Token): Jak szybko AI zaczyna myśleć nad odpowiedzią? To kluczowe dla postrzeganej szybkości Large Language Model (LLM).
- TTFB (Time to First Byte): Jak szybko słyszysz pierwszy dźwięk odpowiedzi AI? Mierzy to cały pipeline – od transkrypcji, przez przetwarzanie, po syntezę mowy.
Aby sprostać temu wyzwaniu, Safina wykorzystuje wysoko zintegrowany pipeline o dużej szybkości.
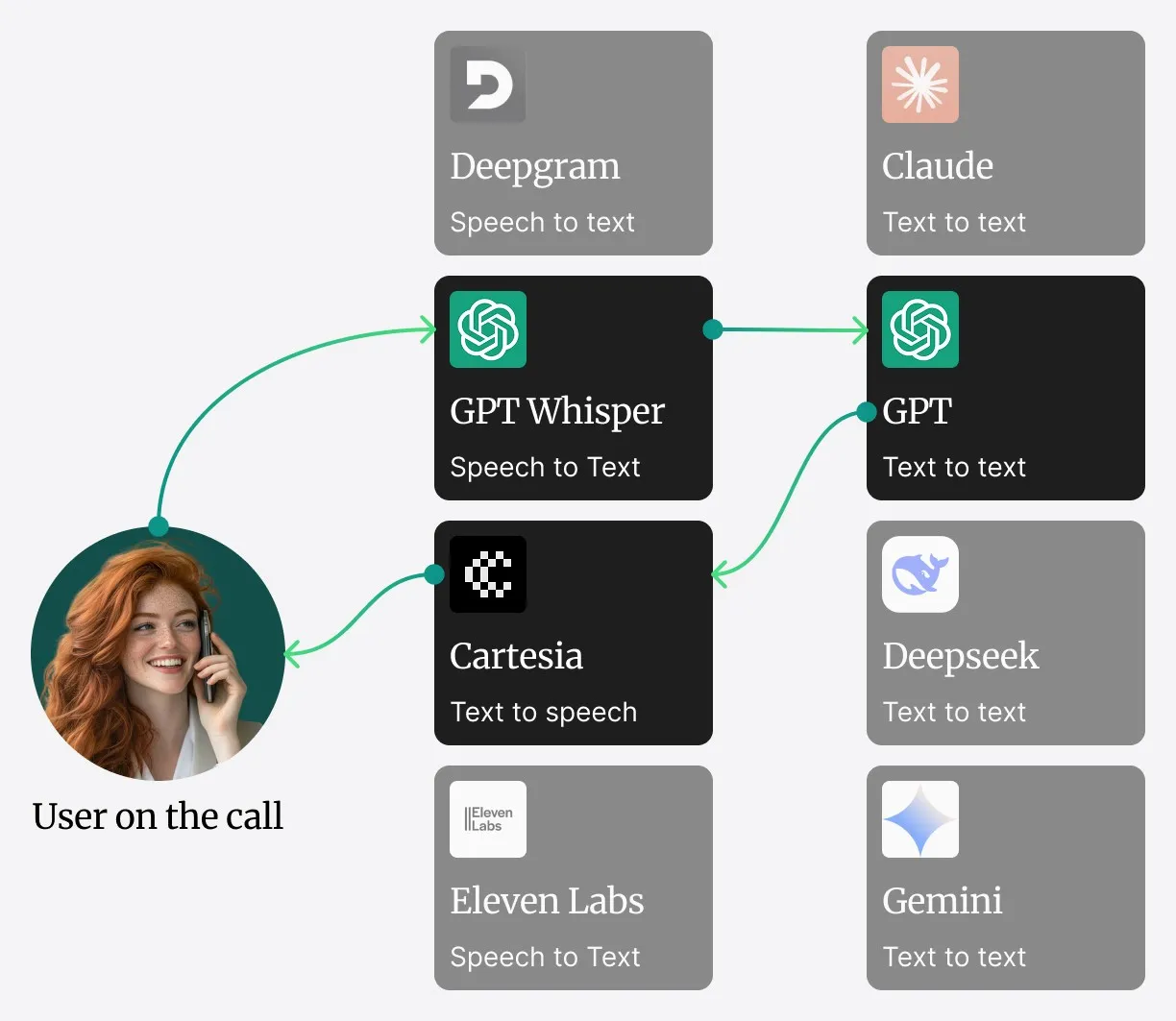
Zintegrowana architektura Safiny
Zamiast stawiać na rozproszony system mikroserwisów, który może powodować opóźnienia sieciowe, kluczowe komponenty Safiny – Speech-to-Text (STT), Large Language Model (LLM) i Text-to-Speech (TTS) – działają w jednej, wysoko zoptymalizowanej usłudze.
Tak przebiega rozmowa:
[🎙 Wejście audio (SIP-Trunk)]
|
v
[📝 Speech-to-Text (STT) – Transkrypcja w czasie rzeczywistym]
|
v
[🧠 Przetwarzanie LLM + Wiedza w kontekście]
|
+---------------+
| Potrzebuje |
| danych |
| zewnętrznych? |
+-------+-------+
Tak | Nie
v | v
[📚 System RAG] [💬 Generowanie odpowiedzi]
\ | /
\ | /
\ | /
\|/
[🔊 Text-to-Speech (TTS) – Synteza mowy]
|
v
[📡 Streaming audio z powrotem do dzwoniącego]- Przechwytywanie audio: Strumień audio na żywo z SIP-Trunk jest bezpośrednio podawany do usługi.
- Przetwarzanie STT: Audio jest natychmiast konwertowane na tekst przez nasz silnik STT.
- Przetwarzanie LLM i wiedza w kontekście: Transkrybowany tekst trafia do głównego LLM. Częste i ważne informacje (np. godziny otwarcia, standardowe powitania) są trzymane bezpośrednio w oknie kontekstowym LLM – dla błyskawicznego dostępu.
- Pobieranie danych (RAG dla dużych zbiorów): Gdy potrzebujesz informacji, których nie ma w bezpośrednim kontekście – na przykład szczegółów zamówienia lub danych z dużej bazy wiedzy – system wywołuje nasz system Retrieval-Augmented Generation (RAG). To most do zewnętrznych źródeł danych. Kompromisy między pamięcią kontekstową a RAG omówimy w Części 2.
- Generowanie TTS: Gdy LLM sformułuje odpowiedź, jest ona bezpośrednio przekazywana do silnika TTS w tej samej usłudze.
- Streaming audio: Silnik TTS generuje audio i strumieniuje je z powrotem do Ciebie – zapewniając płynne doświadczenie rozmowy.
Dlaczego to ważne dla Twojej firmy
Zintegrowane podejście oferuje Ci kilka korzyści:
- Skalowalność: Każdy komponent (STT, LLM, TTS, RAG) może być niezależnie skalowany w zależności od obciążenia. Gdy transkrypcja staje się wąskim gardłem, sklalujesz tylko tę usługę – bez wpływu na pozostałe.
- Odporność na awarie: Gdy jeden mikroserwis ulegnie awarii, nie wyłącza całego systemu. Architektura umożliwia graceful degradation i izolację błędów.
- Rozszerzalność: Kluczowe dla dynamicznych procesów biznesowych. Chcesz zintegrować Safinę z lokalną bazą danych MySQL? Albo z własnym systemem ERP? Możesz tworzyć nowe integracje, które nasłuchują zdarzeń pobierania danych i łączą się ze źródłami danych przez bezpieczne API. Bazowy system Safiny nie wymaga do tego przebudowy.
Następna część: Mózg
Omówiliśmy „układ nerwowy”, który umożliwia Safinie reagowanie w czasie rzeczywistym. Ale jak wygląda „mózg”? Jak Safina rozumie złożone zapytania i uzyskuje dostęp do specyficznej bazy wiedzy Twojej firmy?
W następnym artykule omawiamy Część 2: Mózg – Kontekst vs. RAG dla wiedzy firmowej. Dyskutujemy o kompromisach między przechowywaniem danych w kontekście dla szybkości a wykorzystaniem RAG dla dostępu do obszernych baz wiedzy. Śledź nas dalej, aby dowiedzieć się, jak wyposażyć swoją infrastrukturę firmową w prawdziwie inteligentny głos.