

Willkommen zur Serie “Einblick in Safina AI”! Hier bekommst Du einen exklusiven Blick hinter die Kulissen der Technologie, die unseren KI-Telefonassistenten antreibt. Die Serie richtet sich an technische Fachkräfte, Systemarchitekten und alle, die wissen wollen, wie robuste, unternehmenstaugliche KI-Lösungen für Sprache entstehen.In der heutigen Geschäftswelt geht es bei Telefonie längst nicht mehr nur ums Verbinden von Anrufen. Es geht darum, intelligente, reaktionsschnelle und automatisierte Erlebnisse zu schaffen. Eine KI, die Anrufe entgegennimmt, Termine bucht und komplexe Fragen beantwortet, braucht eine Architektur, die auf Geschwindigkeit, Zuverlässigkeit und tiefe Integration ausgelegt ist.In dieser Serie schauen wir uns die Schlüsselkomponenten von Safinas “Gehirn” und “Nervensystem” an.
Die Serie “Einblick in Safina AI”
- Teil 1: Die Kernarchitektur – Echtzeit-KI für Sprache (Du bist hier)
- Teil 2: Das Gehirn – Kontext vs. RAG für Unternehmenswissen
- Teil 3: Die Sinne – Multimodale Eingaben mit Sprache-zu-Text (STT)
- Teil 4: Die Stimme – Menschenähnliches Text-zu-Sprache (TTS) mit niedriger Latenz
Die Herausforderung: Echtzeitgespräche sind mehr als nur Anfrage-Antwort
Eine Webanfrage folgt einem einfachen Muster: Anfrage, Verarbeitung, Antwort. Ein Echtzeitgespräch ist grundlegend anders. Es ist ein kontinuierlicher, bidirektionaler Datenstrom, bei dem Latenz nicht nur eine Leistungsmetrik ist, sondern ein zentraler Teil des Nutzererlebnisses.Schon eine Verzögerung von wenigen hundert Millisekunden kann eine KI langsam und unnatürlich wirken lassen. Deshalb sind Metriken wie Time to First Token (TTFT) und Time to First Byte (TTFB) entscheidend:
- TTFT (Time to First Token): Wie schnell beginnt die KI, über eine Antwort nachzudenken? Das ist entscheidend für die wahrgenommene Geschwindigkeit des Large Language Models (LLM).
- TTFB (Time to First Byte): Wie schnell hörst Du den ersten Ton der KI-Antwort? Das misst die gesamte Pipeline – von Transkription über Verarbeitung bis zur Sprachsynthese.
Um diese Herausforderung zu meistern, setzt Safina auf eine hochintegrierte Hochgeschwindigkeits-Pipeline.
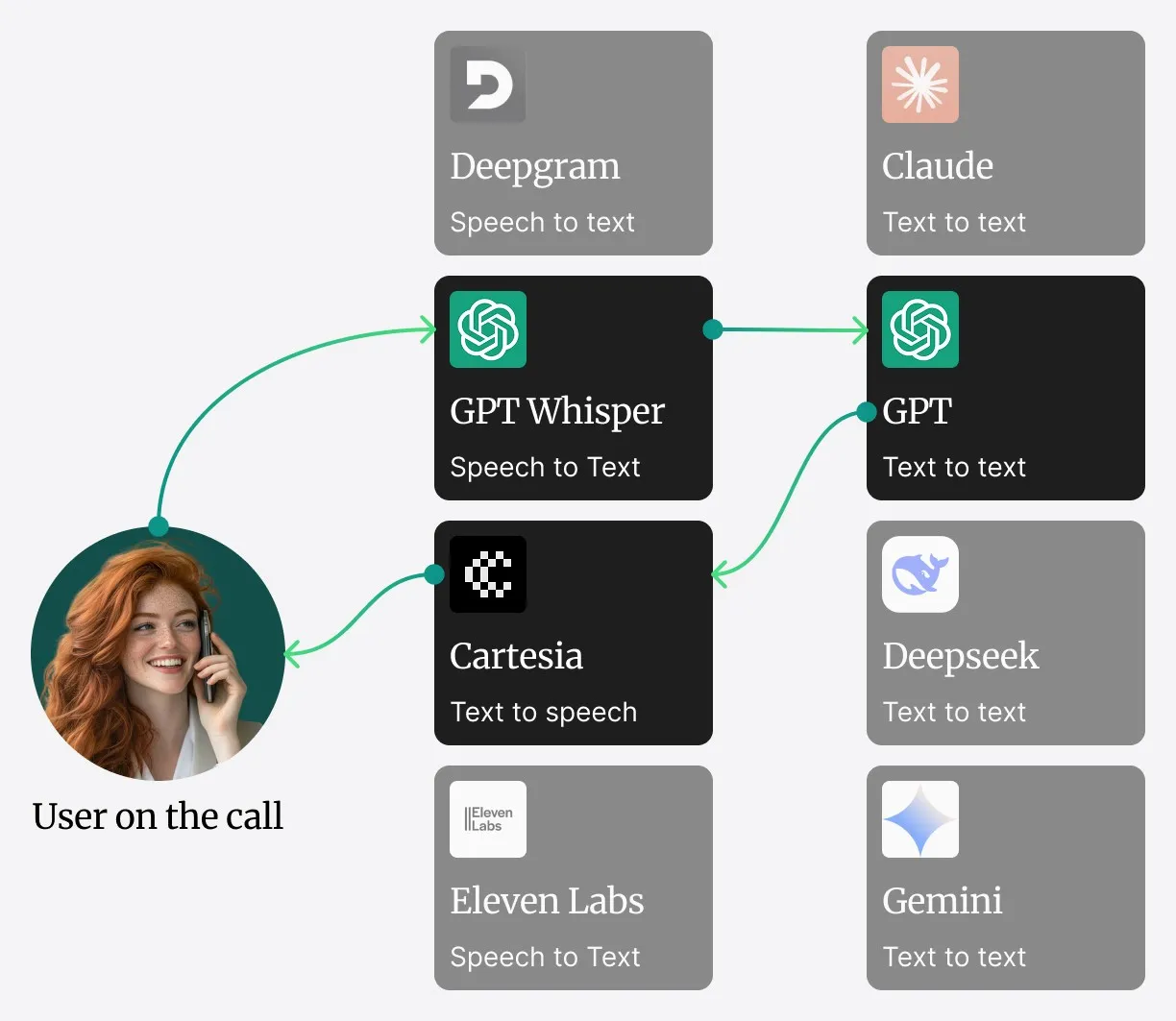
Safinas integrierte Architektur
Statt auf ein verteiltes System von Microservices zu setzen, das Netzwerklatenz verursachen kann, arbeiten Safinas Kernkomponenten – Speech-to-Text (STT), Large Language Model (LLM) und Text-to-Speech (TTS) – in einem einzigen, hochoptimierten Dienst.
So läuft ein Gespräch ab:
[🎙 Audioeingang (SIP-Trunk)]
|
v
[📝 Speech-to-Text (STT) – Transkription in Echtzeit]
|
v
[🧠 LLM-Verarbeitung + In-Kontext-Wissen]
|
+---------------+
| Benötigt |
| externe |
| Daten? |
+-------+-------+
Ja | Nein
v | v
[📚 RAG-System] [💬 Antwort generieren]
\ | /
\ | /
\ | /
\|/
[🔊 Text-to-Speech (TTS) – Sprachsynthese]
|
v
[📡 Audio-Streaming zurück an Anrufer]- Audio-Aufnahme: Der Live-Audiostrom vom SIP-Trunk wird direkt in den Dienst eingespeist.
- STT-Verarbeitung: Das Audio wird sofort von unserer STT-Engine in Text umgewandelt.
- LLM-Verarbeitung & In-Kontext-Wissen: Der transkribierte Text geht ans Kern-LLM. Häufige und wichtige Infos (z. B. Geschäftszeiten, Standardbegrüßungen) werden direkt im Kontextfenster des LLM gehalten – für blitzschnellen Abruf.
- Datenabruf (RAG für große Datenmengen): Brauchst Du Infos, die nicht im unmittelbaren Kontext sind – etwa Bestelldetails oder Daten aus einer großen Wissensdatenbank – ruft das System unser Retrieval-Augmented Generation (RAG)-System auf. Das ist die Brücke zu externen Datenquellen. Die Kompromisse zwischen In-Kontext-Speicher und RAG schauen wir uns in Teil 2 an.
- TTS-Generierung: Sobald das LLM eine Antwort formuliert, wird sie direkt an die TTS-Engine im selben Dienst weitergeleitet.
- Audio-Streaming: Die TTS-Engine erzeugt das Audio und streamt es an Dich zurück – für ein flüssiges Gesprächserlebnis.
Warum das für Dein Unternehmen wichtig ist
Der integrierte Ansatz bietet Dir mehrere Vorteile:
- Skalierbarkeit: Jede Komponente (STT, LLM, TTS, RAG) kann je nach Last unabhängig skaliert werden. Wird die Transkription zum Engpass, skalierst Du nur diesen Dienst – ohne die anderen zu beeinträchtigen.
- Ausfallsicherheit: Fällt ein Microservice aus, legt er nicht das ganze System lahm. Die Architektur ermöglicht eine graceful degradation und Fehlerisolierung.
- Erweiterbarkeit: Für dynamische Geschäftsabläufe entscheidend. Möchtest Du Safina in eine lokale MySQL-Datenbank integrieren? Oder in ein eigenes ERP-System? Du kannst neue Integrationen erstellen, die auf Datenabrufereignisse lauschen und sich über eine sichere API mit Deinen Datenquellen verbinden. Das Kernsystem von Safina muss dafür nicht neu entwickelt werden.
Nächster Teil: Das Gehirn
Wir haben das “Nervensystem” behandelt, das Safina ermöglicht, in Echtzeit zu reagieren. Aber wie sieht es mit dem “Gehirn” aus? Wie versteht Safina komplexe Anfragen und greift auf die spezifische Wissensdatenbank Deines Unternehmens zu?
Im nächsten Artikel geht es um Teil 2: Das Gehirn – Kontext vs. RAG für Unternehmenswissen. Wir diskutieren die Kompromisse zwischen Datenhaltung im Kontext für Geschwindigkeit und der Nutzung von RAG für den Zugriff auf umfangreiche Wissensdatenbanken.Bleib dran, um zu erfahren, wie Du Deine Unternehmensinfrastruktur mit einer wirklich intelligenten Stimme ausstattest.