

Welcome to the “Inside Safina AI” series! Here you’ll get an exclusive look behind the scenes at the technology powering our AI phone assistant. This series is aimed at technical professionals, system architects, and anyone who wants to understand how robust, enterprise-grade voice AI solutions are built. In today’s business world, telephony is no longer just about connecting calls. It’s about creating intelligent, responsive, and automated experiences. An AI that answers calls, books appointments, and handles complex questions needs an architecture built for speed, reliability, and deep integration. In this series, we’ll examine the key components of Safina’s “brain” and “nervous system.”
The “Inside Safina AI” Series
- Part 1: The Core Architecture – Real-Time Voice AI (You are here)
- Part 2: The Brain – Context vs. RAG for Business Knowledge
- Part 3: The Senses – Multimodal Input with Speech-to-Text (STT)
- Part 4: The Voice – Human-Like Text-to-Speech (TTS) with Low Latency
The Challenge: Real-Time Conversations Are More Than Request-Response
A web request follows a simple pattern: request, process, respond. A real-time conversation is fundamentally different. It’s a continuous, bidirectional data stream where latency isn’t just a performance metric – it’s a core part of the user experience. Even a delay of a few hundred milliseconds can make an AI feel slow and unnatural. That’s why metrics like Time to First Token (TTFT) and Time to First Byte (TTFB) are critical:
- TTFT (Time to First Token): How quickly does the AI start thinking about a response? This is crucial for the perceived speed of the Large Language Model (LLM).
- TTFB (Time to First Byte): How quickly do you hear the first sound of the AI’s response? This measures the entire pipeline – from transcription to processing to speech synthesis.
To tackle this challenge, Safina uses a highly integrated high-speed pipeline.
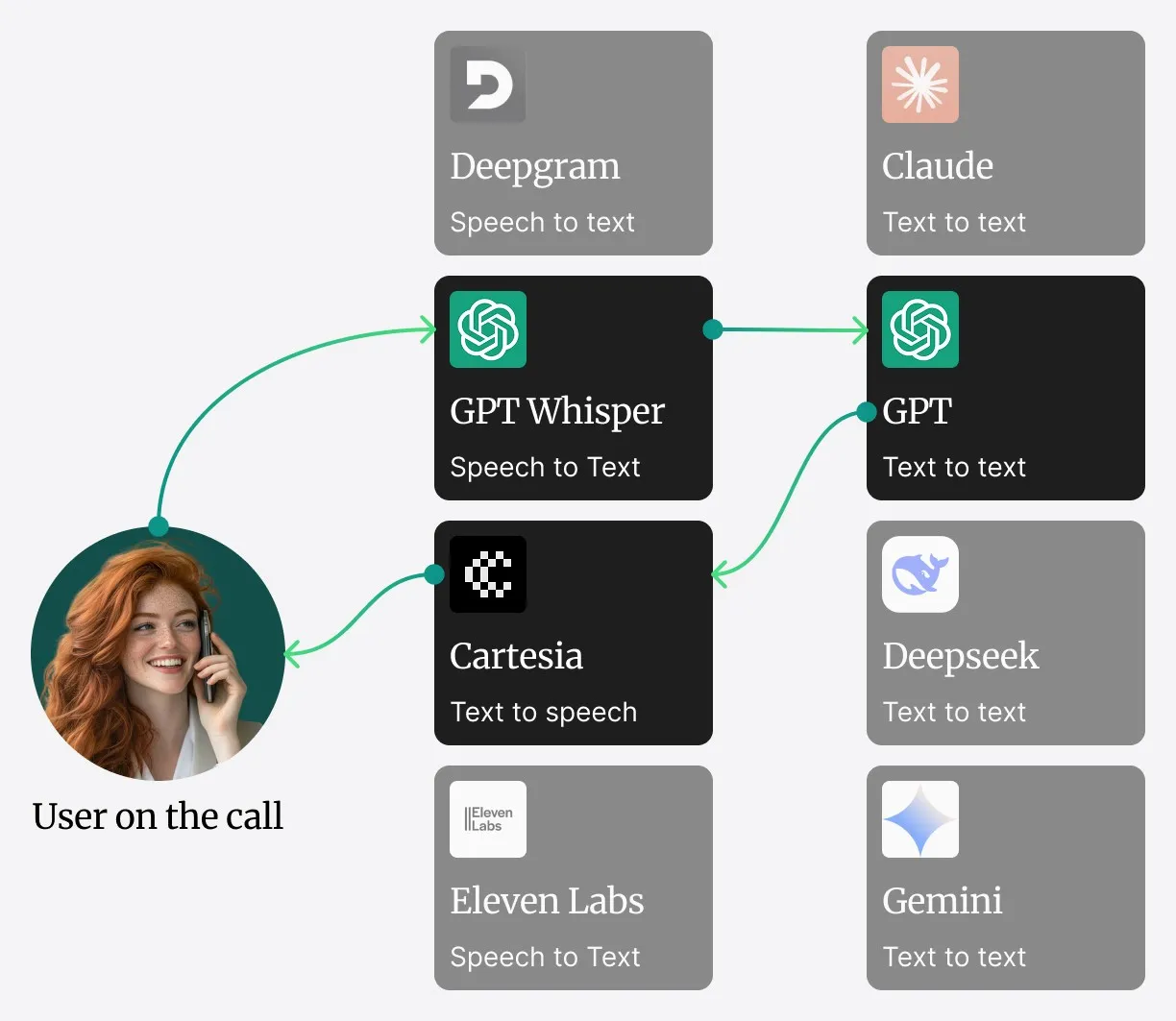
Safina’s Integrated Architecture
Rather than relying on a distributed microservices system that can introduce network latency, Safina’s core components – Speech-to-Text (STT), Large Language Model (LLM), and Text-to-Speech (TTS) – operate within a single, highly optimized service.
Here’s how a conversation works:
[🎙 Audio Input (SIP Trunk)]
|
v
[📝 Speech-to-Text (STT) – Real-Time Transcription]
|
v
[🧠 LLM Processing + In-Context Knowledge]
|
+---------------+
| Needs |
| external |
| data? |
+-------+-------+
Yes | No
v | v
[📚 RAG System] [💬 Generate Response]
\ | /
\ | /
\ | /
\|/
[🔊 Text-to-Speech (TTS) – Speech Synthesis]
|
v
[📡 Audio Streaming Back to Caller]- Audio Capture: The live audio stream from the SIP trunk is fed directly into the service.
- STT Processing: The audio is immediately converted to text by our STT engine.
- LLM Processing & In-Context Knowledge: The transcribed text goes to the core LLM. Frequently used and important information (e.g., business hours, standard greetings) is kept directly in the LLM’s context window – for lightning-fast retrieval.
- Data Retrieval (RAG for Large Datasets): When information not in the immediate context is needed – such as order details or data from a large knowledge base – the system calls our Retrieval-Augmented Generation (RAG) system. This is the bridge to external data sources. We’ll explore the trade-offs between in-context memory and RAG in Part 2.
- TTS Generation: As soon as the LLM formulates a response, it’s passed directly to the TTS engine within the same service.
- Audio Streaming: The TTS engine generates the audio and streams it back to you – for a smooth conversational experience.
Why This Matters for Your Business
The integrated approach offers several advantages:
- Scalability: Each component (STT, LLM, TTS, RAG) can be scaled independently based on load. If transcription becomes a bottleneck, you scale just that service – without affecting the others.
- Resilience: If a microservice fails, it doesn’t take down the entire system. The architecture enables graceful degradation and fault isolation.
- Extensibility: Critical for dynamic business workflows. Want to integrate Safina with a local MySQL database? Or with your own ERP system? You can create new integrations that listen for data retrieval events and connect to your data sources via a secure API. Safina’s core system doesn’t need to be rebuilt for that.
Next Part: The Brain
We’ve covered the “nervous system” that enables Safina to respond in real time. But what about the “brain”? How does Safina understand complex queries and access your company’s specific knowledge base?
In the next article, we’ll look at Part 2: The Brain – Context vs. RAG for Business Knowledge. We’ll discuss the trade-offs between keeping data in context for speed and using RAG to access extensive knowledge bases. Stay tuned to learn how to give your business infrastructure a truly intelligent voice.