

Bienvenue dans la série « Plongée dans Safina AI » ! Tu vas avoir un aperçu exclusif des coulisses de la technologie qui propulse notre assistant téléphonique IA. Cette série s’adresse aux professionnels techniques, aux architectes système et à tous ceux qui veulent savoir comment naissent des solutions IA vocales robustes et adaptées aux entreprises. Dans le monde des affaires actuel, la téléphonie ne se résume plus à connecter des appels. Il s’agit de créer des expériences intelligentes, réactives et automatisées. Une IA qui prend des appels, réserve des rendez-vous et répond à des questions complexes nécessite une architecture conçue pour la vitesse, la fiabilité et l’intégration profonde. Dans cette série, nous examinons les composants clés du « cerveau » et du « système nerveux » de Safina.
La série « Plongée dans Safina AI »
- Partie 1 : L’architecture centrale — IA en temps réel pour la voix (tu es ici)
- Partie 2 : Le cerveau — Contexte vs. RAG pour les connaissances d’entreprise
- Partie 3 : Les sens — Entrées multimodales avec la reconnaissance vocale (STT)
- Partie 4 : La voix — Synthèse vocale (TTS) proche de l’humain avec faible latence
Le défi : les conversations en temps réel sont plus qu’un simple schéma requête-réponse
Une requête web suit un schéma simple : requête, traitement, réponse. Une conversation en temps réel est fondamentalement différente. C’est un flux de données continu et bidirectionnel, où la latence n’est pas seulement une métrique de performance, mais une composante centrale de l’expérience utilisateur. Un délai de quelques centaines de millisecondes suffit à rendre une IA lente et artificielle. C’est pourquoi des métriques comme le Time to First Token (TTFT) et le Time to First Byte (TTFB) sont décisives :
- TTFT (Time to First Token) : À quelle vitesse l’IA commence-t-elle à réfléchir à une réponse ? C’est décisif pour la vitesse perçue du Large Language Model (LLM).
- TTFB (Time to First Byte) : À quelle vitesse entends-tu le premier son de la réponse de l’IA ? Cela mesure l’ensemble du pipeline — de la transcription au traitement jusqu’à la synthèse vocale.
Pour relever ce défi, Safina s’appuie sur un pipeline haute vitesse hautement intégré.
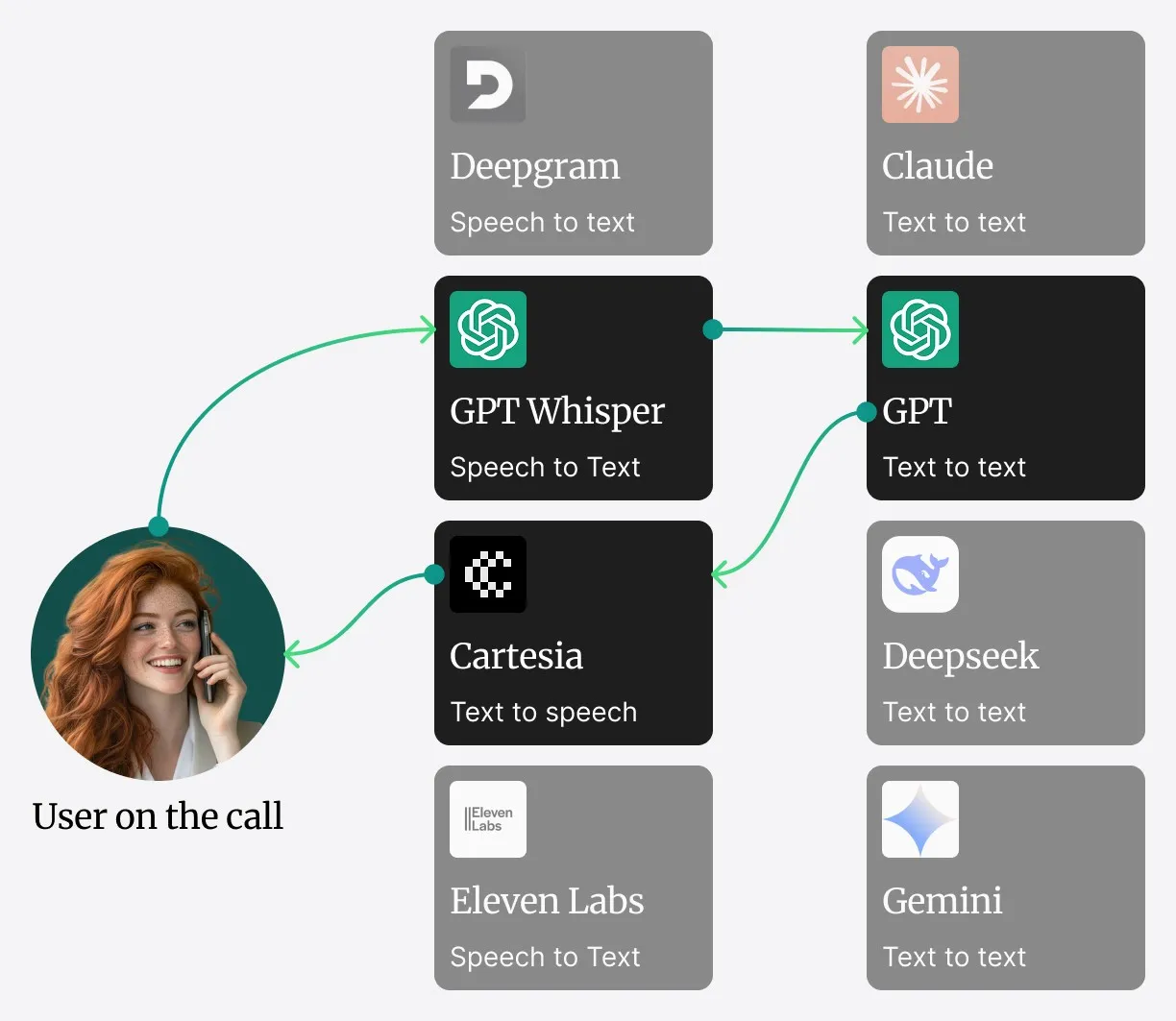
L’architecture intégrée de Safina
Au lieu de miser sur un système distribué de microservices pouvant engendrer de la latence réseau, les composants centraux de Safina — Speech-to-Text (STT), Large Language Model (LLM) et Text-to-Speech (TTS) — fonctionnent au sein d’un service unique hautement optimisé.
Voici comment se déroule une conversation :
[🎙 Entrée audio (SIP-Trunk)]
|
v
[📝 Speech-to-Text (STT) – Transcription en temps réel]
|
v
[🧠 Traitement LLM + Connaissances en contexte]
|
+---------------+
| Nécessite |
| des données |
| externes ? |
+-------+-------+
Oui | Non
v | v
[📚 Système RAG] [💬 Générer la réponse]
\ | /
\ | /
\ | /
\|/
[🔊 Text-to-Speech (TTS) – Synthèse vocale]
|
v
[📡 Streaming audio retour à l'appelant]- Capture audio : Le flux audio en direct du SIP-Trunk est directement injecté dans le service.
- Traitement STT : L’audio est immédiatement converti en texte par notre moteur STT.
- Traitement LLM et connaissances en contexte : Le texte transcrit est transmis au LLM central. Les informations fréquentes et importantes (par ex. horaires d’ouverture, messages d’accueil standards) sont maintenues directement dans la fenêtre de contexte du LLM — pour un accès ultra-rapide.
- Récupération de données (RAG pour les grands volumes) : Si tu as besoin d’informations qui ne sont pas dans le contexte immédiat — comme des détails de commande ou des données d’une grande base de connaissances — le système fait appel à notre système de Retrieval-Augmented Generation (RAG). C’est le pont vers les sources de données externes. Nous examinerons les compromis entre mémoire en contexte et RAG dans la partie 2.
- Génération TTS : Dès que le LLM formule une réponse, elle est transmise directement au moteur TTS dans le même service.
- Streaming audio : Le moteur TTS génère l’audio et le diffuse vers toi en retour — pour une expérience de conversation fluide.
Pourquoi c’est important pour ton entreprise
L’approche intégrée t’offre plusieurs avantages :
- Extensibilité : Chaque composant (STT, LLM, TTS, RAG) peut être mis à l’échelle indépendamment selon la charge. Si la transcription devient un goulot d’étranglement, tu ne mets à l’échelle que ce service — sans affecter les autres.
- Résilience : Si un microservice tombe en panne, il ne paralyse pas l’ensemble du système. L’architecture permet une dégradation gracieuse et une isolation des erreurs.
- Extensibilité : Crucial pour les processus métier dynamiques. Tu souhaites intégrer Safina avec une base de données MySQL locale ? Ou avec ton propre ERP ? Tu peux créer de nouvelles intégrations qui écoutent les événements de récupération de données et se connectent à tes sources de données via une API sécurisée. Le système central de Safina n’a pas besoin d’être redéveloppé pour cela.
Prochaine partie : le cerveau
Nous avons couvert le « système nerveux » qui permet à Safina de réagir en temps réel. Mais qu’en est-il du « cerveau » ? Comment Safina comprend-elle des demandes complexes et accède-t-elle à la base de connaissances spécifique de ton entreprise ?
Dans le prochain article, nous abordons Partie 2 : Le cerveau — Contexte vs. RAG pour les connaissances d’entreprise. Nous y discutons des compromis entre le stockage de données en contexte pour la vitesse et l’utilisation du RAG pour accéder à de vastes bases de connaissances. Reste connecté pour découvrir comment doter ton infrastructure d’entreprise d’une voix véritablement intelligente.