

Bienvenido a la serie “Dentro de Safina AI”. Aquí obtendrás una mirada exclusiva entre bastidores a la tecnología que impulsa nuestro asistente telefónico de IA. La serie está dirigida a profesionales técnicos, arquitectos de sistemas y todos los que quieran saber cómo se crean soluciones de IA robustas y preparadas para empresas en el ámbito de la voz. En el mundo empresarial actual, la telefonía ya no se trata solo de conectar llamadas. Se trata de crear experiencias inteligentes, reactivas y automatizadas. Una IA que atiende llamadas, reserva citas y responde preguntas complejas necesita una arquitectura diseñada para velocidad, fiabilidad e integración profunda. En esta serie analizamos los componentes clave del “cerebro” y el “sistema nervioso” de Safina.
La serie “Dentro de Safina AI”
- Parte 1: La arquitectura central - IA en tiempo real para voz (Estás aquí)
- Parte 2: El cerebro - Contexto vs. RAG para el conocimiento empresarial
- Parte 3: Los sentidos - Entradas multimodales con voz a texto (STT)
- Parte 4: La voz - Texto a voz (TTS) similar al humano con baja latencia
El desafío: las conversaciones en tiempo real son más que solicitud-respuesta
Una solicitud web sigue un patrón simple: solicitud, procesamiento, respuesta. Una conversación en tiempo real es fundamentalmente diferente. Es un flujo de datos continuo y bidireccional en el que la latencia no es solo una métrica de rendimiento, sino una parte central de la experiencia del usuario. Una demora de apenas unos cientos de milisegundos puede hacer que una IA parezca lenta y antinatural. Por eso, métricas como Time to First Token (TTFT) y Time to First Byte (TTFB) son cruciales:
- TTFT (Time to First Token): ¿Qué tan rápido empieza la IA a pensar en una respuesta? Esto es decisivo para la velocidad percibida del Large Language Model (LLM).
- TTFB (Time to First Byte): ¿Qué tan rápido escuchas el primer sonido de la respuesta de la IA? Esto mide todo el pipeline, desde la transcripción pasando por el procesamiento hasta la síntesis de voz.
Para superar este desafío, Safina utiliza un pipeline de alta velocidad altamente integrado.
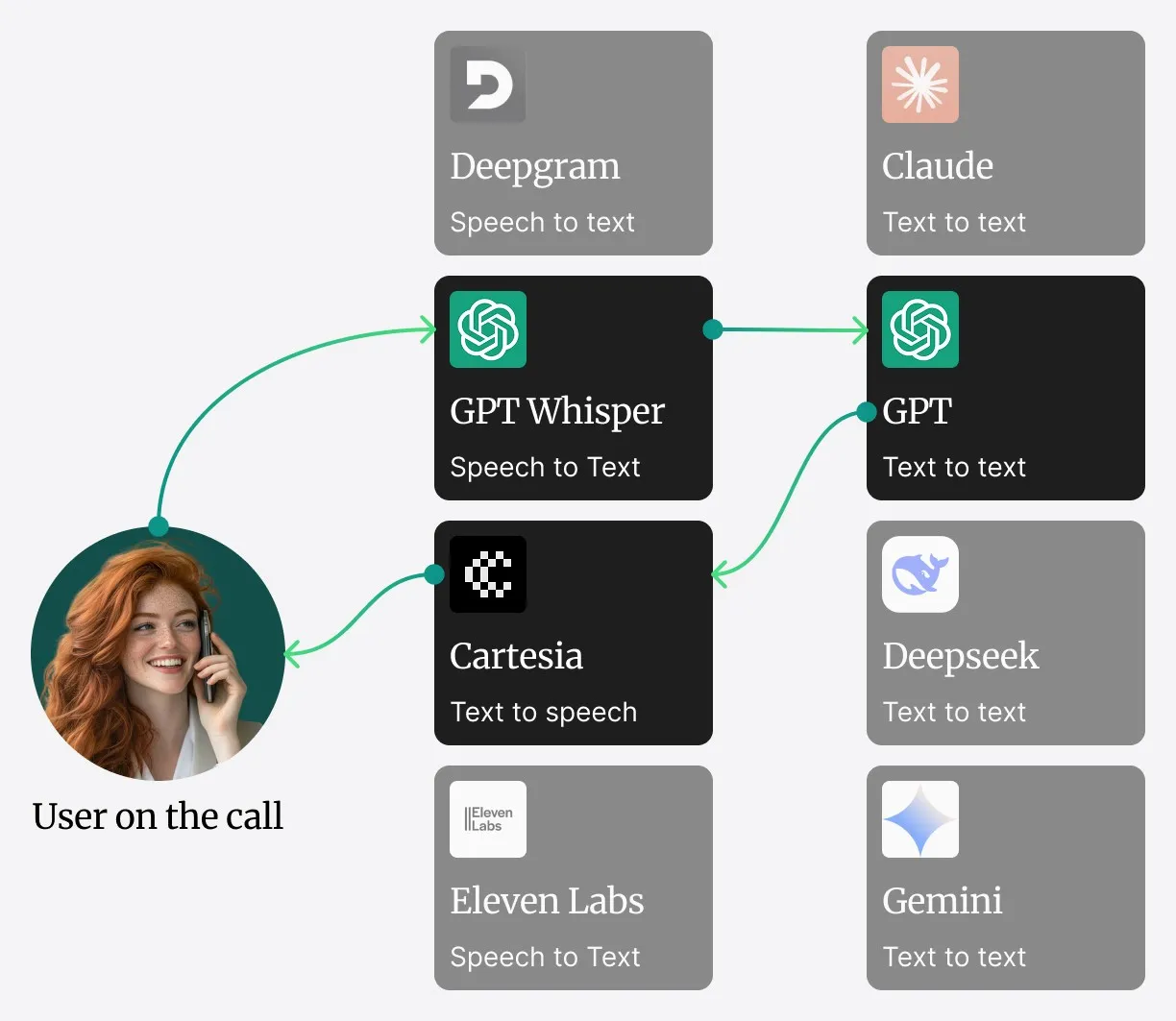
La arquitectura integrada de Safina
En lugar de depender de un sistema distribuido de microservicios que puede causar latencia de red, los componentes centrales de Safina — Speech-to-Text (STT), Large Language Model (LLM) y Text-to-Speech (TTS) — funcionan en un único servicio altamente optimizado.
Así transcurre una conversación:
[🎙 Entrada de audio (SIP-Trunk)]
|
v
[📝 Speech-to-Text (STT) - Transcripción en tiempo real]
|
v
[🧠 Procesamiento LLM + Conocimiento en contexto]
|
+---------------+
| ¿Necesita |
| datos |
| externos? |
+-------+-------+
Sí | No
v | v
[📚 Sistema RAG] [💬 Generar respuesta]
\ | /
\ | /
\ | /
\|/
[🔊 Text-to-Speech (TTS) - Síntesis de voz]
|
v
[📡 Streaming de audio de vuelta al llamante]- Captura de audio: El flujo de audio en vivo desde el SIP-Trunk se alimenta directamente al servicio.
- Procesamiento STT: El audio se convierte inmediatamente en texto por nuestro motor STT.
- Procesamiento LLM y conocimiento en contexto: El texto transcrito va al LLM central. La información frecuente e importante (p. ej., horarios de apertura, saludos estándar) se mantiene directamente en la ventana de contexto del LLM, para una recuperación ultrarrápida.
- Recuperación de datos (RAG para grandes volúmenes de datos): Si necesitas información que no está en el contexto inmediato, como detalles de pedidos o datos de una gran base de conocimiento, el sistema llama a nuestro sistema de Retrieval-Augmented Generation (RAG). Es el puente hacia fuentes de datos externas. Los compromisos entre memoria en contexto y RAG los analizamos en la Parte 2.
- Generación TTS: En cuanto el LLM formula una respuesta, se transmite directamente al motor TTS en el mismo servicio.
- Streaming de audio: El motor TTS genera el audio y lo transmite de vuelta, para una experiencia de conversación fluida.
Por qué esto es importante para tu empresa
El enfoque integrado te ofrece varias ventajas:
- Escalabilidad: Cada componente (STT, LLM, TTS, RAG) puede escalarse de forma independiente según la carga. Si la transcripción se convierte en un cuello de botella, solo escalas ese servicio, sin afectar a los demás.
- Resiliencia: Si un microservicio falla, no paraliza todo el sistema. La arquitectura permite una degradación elegante y el aislamiento de errores.
- Extensibilidad: Decisivo para flujos de negocio dinámicos. ¿Quieres integrar Safina con una base de datos MySQL local? ¿O con tu propio sistema ERP? Puedes crear nuevas integraciones que escuchen eventos de recuperación de datos y se conecten a tus fuentes de datos a través de una API segura. El sistema central de Safina no necesita ser rediseñado para ello.
Siguiente parte: El cerebro
Hemos cubierto el “sistema nervioso” que permite a Safina reaccionar en tiempo real. Pero, ¿qué pasa con el “cerebro”? ¿Cómo entiende Safina consultas complejas y accede a la base de conocimiento específica de tu empresa?
En el próximo artículo veremos la Parte 2: El cerebro - Contexto vs. RAG para el conocimiento empresarial. Discutiremos los compromisos entre mantener datos en contexto para velocidad y usar RAG para acceder a bases de conocimiento extensas. Sigue atento para descubrir cómo equipar tu infraestructura empresarial con una voz verdaderamente inteligente.