Einblick in Safina AI, Teil 2: Das Gehirn – Kontext vs. RAG für Unternehmenswissen
Erfahre, wie Safina AI mit In-Kontext-Speicher und RAG blitzschnell und tief auf Unternehmenswissen zugreift – für präzise, natürliche Echtzeitgespräche.

Insight

Einblick in Safina AI, Teil 2: Das Gehirn – Kontext vs. RAG für Unternehmenswissen
Willkommen zurück zu unserer Serie „Einblick in Safina AI“. In Teil 1: Die Kernarchitektur – Echtzeit-KI für Sprache haben wir die hochintegrierte Hochgeschwindigkeits-Pipeline untersucht, die es Safina ermöglicht, mit minimaler Latenz zuzuhören, zu denken und zu sprechen. Wir haben das „Nervensystem“ unserer KI behandelt. Jetzt schauen wir uns ihr „Gehirn“ an: Wie weiß Safina eigentlich Dinge über Dein Unternehmen?
Wissen ist der Schlüssel
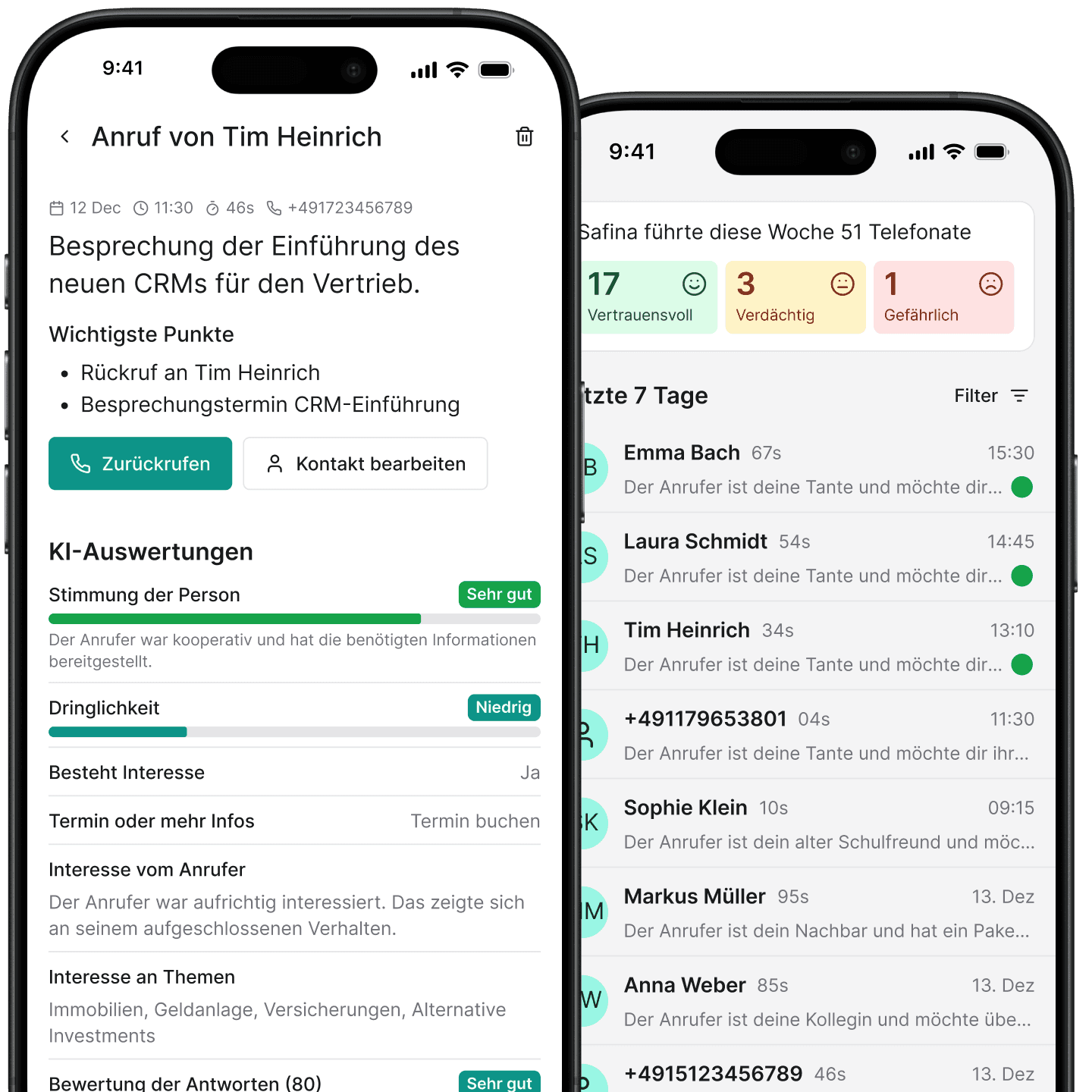
Ein KI-Telefonassistent ist nur so gut wie sein Wissen. Ob es darum geht, Deine Geschäftszeiten abzurufen oder die Bestellhistorie eines Kunden nachzuschlagen – der Zugriff auf die richtigen Informationen zur richtigen Zeit ist entscheidend.Safina nutzt dafür einen hybriden Ansatz mit zwei leistungsstarken Techniken:
In-Kontext-Speicher – das Kurzzeitgedächtnis der KI
Retrieval-Augmented Generation (RAG) – das Langzeitgedächtnis der KI
Methode 1: In-Kontext-Speicher – Das Kurzzeitgedächtnis
Der schnellste Weg für ein Large Language Model (LLM), auf Informationen zuzugreifen, ist, wenn diese bereits Teil seiner unmittelbaren „Gedanken“ sind – das sogenannte Kontextfenster. Du kannst es Dir wie das Arbeitsgedächtnis der KI vorstellen.Wenn Du Deinen Safina-Assistenten einrichtest, hinterlegst Du Kerndetails über Dein Unternehmen. Diese werden für jeden Anruf direkt ins Kontextfenster geladen.Perfekt geeignet für den In-Kontext-Speicher sind:
Unternehmens-Eckdaten: Name, Adresse, Telefonnummer, Website
Standard-Öffnungszeiten: „Wir haben Montag–Freitag von 9–17 Uhr geöffnet.“
FAQs: Antworten auf gängige Fragen wie „Bietet ihr kostenlosen Versand an?“
Kernanweisungen: „Du bist ein freundlicher Assistent für [Firmenname]. Hilf Anrufern effizient.“
Vorteil: Blitzschnelle Antworten, da keine externen Abfragen nötig sind – ideal für häufige, einfache Fragen.Einschränkung: Das Kontextfenster ist begrenzt. Große Produktkataloge, komplette Kundenhistorien oder tausende Dokumente passen hier nicht hinein. Dafür braucht es eine Langzeitgedächtnis-Lösung.
Methode 2: Retrieval-Augmented Generation (RAG) – Das Langzeitgedächtnis
Wenn ein Anrufer eine Frage stellt wie: „Kannst Du den Status meiner Bestellung von letztem Dienstag prüfen?“ oder „Was sind die technischen Daten von Produkt X?“ – dann kommt RAG ins Spiel.RAG verbindet das LLM mit Deinen umfangreichen Wissensdatenbanken und ermöglicht es, in Echtzeit Informationen aus nahezu jeder Quelle nachzuschlagen.So funktioniert der RAG-Workflow:
Absichtserkennung: Das LLM erkennt, dass externe Daten nötig sind.
Anfrageformulierung: Die Frage wird in eine strukturierte Abfrage für die passende Datenquelle umgewandelt.
Datenabruf: Safina greift sicher auf Deine Daten zu – z. B.:
Strukturierte Daten: MySQL, PostgreSQL, NoSQL (z. B. MongoDB)
Unstrukturierte Daten: Semantische Suche in Dokumenten, PDFs, Websites, Vektordatenbanken oder Objektspeichern (Amazon S3, Google Cloud Storage)
Kontext-Injektion: Die gefundenen Infos werden ins Kontextfenster eingefügt.
Antwortgenerierung: Das LLM formuliert eine natürliche Antwort, z. B.:„Ich habe nachgesehen: Deine Bestellung von letztem Dienstag wurde versandt. Die Sendungsverfolgungsnummer lautet …“
Safinas hybrider Ansatz: Schnell + Tief
Safina zwingt Dich nicht, Dich für eine Methode zu entscheiden – es werden beide intelligent kombiniert:
Zuerst prüft Safina, ob die Antwort im In-Kontext-Speicher liegt.
Nur wenn nötig wird die RAG-Pipeline aktiviert.
Vorteile:
Blitzschnelle Antworten auf häufige Fragen
Tiefe, präzise Antworten auf komplexe, datengesteuerte Anfragen
Durch die Verbindung von Arbeitsgedächtnis und Langzeitgedächtnis bietet Safina ein Gesprächserlebnis, das schnell und fundiert ist.
Bereit, Deiner KI ein Gehirn zu geben?
Verbinde Safina mit Deinen Wissensquellen – egal ob es nur ein paar wichtige Fakten oder eine komplette Datenbank sind. Erlebe, wie einfach es ist, einen wirklich sachkundigen KI-Assistenten zu erstellen.
Nächster Teil:
Teil 3: Die Sinne – Hochpräzise Sprache-zu-Text (STT) – Erfahre, wie Safina Sprache in Echtzeit versteht, Akzente erkennt und Hintergrundgeräusche filtert.